Scattered Context Grammars research
Contents
- 1 Introduction
- 2 Basic Definitions
- 3 Results
- 3.1 Known Results
- 3.1.1 Generative Power
- 3.1.2 Normal Forms of Propagating Scattered Context Grammars
- 3.1.3 Closure Properties of Propagating Scattered Context Grammars
- 3.1.4 Extended Propagating Scattered Context Grammars
- 3.1.5 Propagating Scattered Context Grammars Using Leftmost Derivations
- 3.1.6 Reduction of Scattered Context Grammars
- 3.2 Own Research
- 3.1 Known Results
- 4 Related Literature
- 5 Contact Information
Introduction
Scattered context grammars were introduced by S. Greibach and J. Hopcroft in 1969 as a straightforward generalization of context-free grammars. Each production of these grammars contains n context-free productions which are applied in parallel to the current sentential form. For example a scattered context production
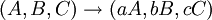
which consists of three context-free productions,
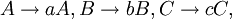
is applicable to the sentential form aAbBcC so that all context-free components are applied in parallel and the nonterminals on their left-hand sides are in the same order as they appear in the sentential form. As a result,
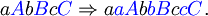
It is easy to see that by adding productions (S → ABC) and (A, B, C) → (a, b, c), where S is the start symbol of the grammar, we can easily describe the non-context-free language
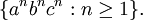
The first advantage of scattered context grammars can be seen here - by using several context-free productions in parallel, we are able to describe some context-sensitive languages. Furthermore, by only extending context-free grammars, which are well studied and used in many practical applications, we preserve the simplicity of language description. In addition, for modeling context dependencies which span over the whole sentential form (for example in the above example), the description is much simpler than when using ordinary context-sensitive grammars.
Basic Definitions
Formal Languages
The reader is expected to be familiar with the basics of formal language theory. This section is intended to describe the used terminology rather than explaining the basics of formal language theory.
An alphabet V is a finite nonempty set, whose members are called symbols. The cardinality of V, |V|, is the number of V's members. A finite sequence of symbols from V is a string or, synonymously, a word over V; specifically, ε is referred to as the empty string. The length of a string x ∈ V *, denoted by |x|, is the number of elements in x. For U ⊆ V, |x|U denotes the number of occurrences of elements from U in a string x. By V*, we denote the set of all strings over V; V+ = V* - {ε}. Any subset L ⊆ V* is a language over V. By alph(x) we denote the set of all symbols occurring in a string x. Set
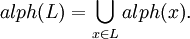
Let x,y ∈ V* be two strings over an alphabet V. The concatenation of x with y, denoted by xy, is the string obtained by appending y to x. For all i ≥ 0 the ith power of x, denoted by xi, is recursively defined as
- x0 = ε and
- xi = x xi-1 for i ≥ 1.
The reversal of x, denoted by rev(x), is x written in the reverse order. Let L1, L2 ⊆ V* be two languages over V. The concatenation of L1 and L2, denoted by L1L2, is defined as
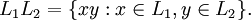
The right quotient of L1 with respect to L2, denoted by L1 / L2, is defined as
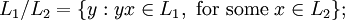
similarly, the left quotient of L1 with respect to L2, denoted by L2 \ L1, is defined as
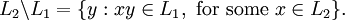
We also use a special type of the right and the left quotient. The exhaustive right quotient of L1 with respect to L2, denoted by L1 // L2, is defined as
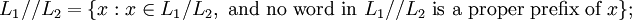
similarly, the exhaustive left quotient of L1 with respect to L2, denoted by L2 \\ L1, is defined as
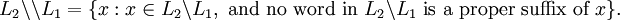
Apart from binary operations, we also make some unary operations with languages. Let L ⊆ T*. The ith power of L, Li, is defined as
- L0 = {ε} and
- Li = L Li-1 for i ≥ 1.
The Kleene star of L, L*, is defined as
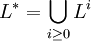
and the Kleene plus of L, L+, is defined as
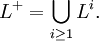
Notice that L+ = L L* = L* L and L* = L+ ∪ {ε}.
References
(pdf) A. Meduna. Automata and Languages: Theory and Applications. Springer, 2000, pp. 920.
(pdf) G. Rozenberg and A. Salomaa. Handbook of Formal Languages. Springer, 1997, pp. 2051.
(pdf) A. Salomaa. Formal Languages. Academic Press, 1973, pp. 322.
Scattered Context Grammars
A scattered context grammar is a quadruple
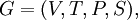
where
- V is the total alphabet,
- T ⊂ V is the set of terminals,
- P is a finite set of productions of the form (A1, ..., An) → (x1, ..., xn), where n ≥ 1, Ai ∈ V-T and xi ∈ V* for all 1 ≤ i ≤ n,
- S ∈ V - T is the start symbol of G.
If
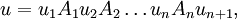
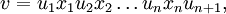
and
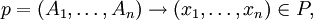
where ui ∈ V* for all 1 ≤ i ≤ n, then G makes a derivation step from u to v according to p, symbolically written as u ⇒ v [p], or, simply, u ⇒ v. In addition, if Ai ∉ alph(ui) for all 1 ≤ i ≤ n, then the direct derivation is leftmost, and we write u lm⇒ v [p]; if Ai ∉ alph(ui+1) for all 1 ≤ i ≤ n, then the direct derivation is rightmost, and we write u rm⇒ v [p]. Set lhs(p) = A1 A2...An, rhs(p) = x1 x2...xn, and len(p) = |A1...An| = n. If len(p) ≥ 2, p is said to be a context-sensitive production, while for len(p) = 1, p is said to be context-free. The scattered context language, is a language generated by a scattered context grammar G = (V, T, P, S), denoted by L(G), and defined as
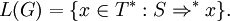
If every derivation step in every successful derivation in G is leftmost, G generates L(G) in a leftmost way. If every step in every successful derivation in G is rightmost, G generates L(G) in a rightmost way. The family of languages generated by scattered context grammars is denoted by
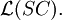
Propagating Scattered Context Grammars
A propagating scattered context grammar is a scattered context grammar G = (V, T, P, S) in which each (A1, ..., An) → (x1, ..., xn) ∈ P satisfies xi ∈ V+ for all 1 ≤ i ≤ n. The propagating scattered context language is a language generated by a propagating scattered context grammar. The family of languages generated by propagating scattered context grammars is denoted by
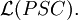 .
.
References
(pdf) S. Greibach, J. Hopcroft. Scattered Context Grammars. Journal of Computer and System Sciences, 1969, pp. 233-247.
Results
Known Results
Generative Power
Based on
(pdf) S. Greibach, J. Hopcroft. Scattered Context Grammars. Journal of Computer and System Sciences, 1969, pp. 233-247.
(pdf) V. Virkkunen. On Scattered Context Grammars. Acta Universitatis Ouluensis, 1973, pp. 75-82.
Results
Theorem
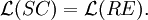
Theorem
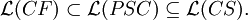
Open Problem
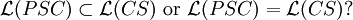
Normal Forms of Propagating Scattered Context Grammars
Based on
(pdf) S. Greibach, J. Hopcroft. Scattered Context Grammars. Journal of Computer and System Sciences, 1969, pp. 233-247.
Definitions
A 2-limited grammar is a propagating scattered context grammar G = (V, T, P, S) such that
- (A1, ..., An) → (w1, ..., wn) ∈ P implies n ≤ 2, and for each 1 ≤ i ≤ n, 1 ≤ |wi| ≤ 2 and wi ∈ (V-{S})*.
- (A) → (w) ∈ P implies A = S.
Results
Theorem If G is a propagating scattered context grammar, then there exists a 2-limited grammar G' with L(G') = L(G).
Closure Properties of Propagating Scattered Context Grammars
Based on
(pdf) S. Greibach, J. Hopcroft. Scattered Context Grammars. Journal of Computer and System Sciences, 1969, pp. 233-247.
Definitions
An abstract family of languages is a pair (T, L ), or L when T is understood, where
- T is a countably infinite set of symbols;
- For each L ∈ L there is a finite set T1 ⊆ T such that L ⊆ T1*;
- L ≠ ø for some L ∈ L;
- L is closed under the operations of union, concatenation, Kleene plus, inverse homomorphism, ε-free homomorphism, and intersection with a regular language.
Results
Theorem The family of propagating scattered context languages is closed under intersection, ε-free substitution, substitution by an ε-free context free language, linear erasing, and permutations.
Theorem The family of propagating scattered context languages is an abstract family of languages.
Theorem If L is a recursively enumerable language, then there exists a propagating scattered context language L' and a homomorphism h such that h(L') = L.
Theorem The family of propagating scattered context languages is not closed under arbitrary homomorphism and quotient by a regular language.
Theorem The emptiness problem is recursively unsolvable for propagating scattered context grammars.
Extended Propagating Scattered Context Grammars
Based on
(pdf) J. Gonczarowski, M. K. Warmuth. Scattered Versus Context-Sensitive Rewriting. Acta Informatica, 1989, pp. 81-95.
Definitions
An extended propagating scattered context grammar is a scattered context grammar G = (V, T, P, S), in which every (A1, ..., An) → (x1, ..., xn) ∈ P satisfies |x1...xn| ≥ n.
Results
Theorem The family of languages generated by extended propagating scattered context grammars coincides with the family of context-sensitive languages.
Propagating Scattered Context Grammars Using Leftmost Derivations
Based on
(pdf) V. Virkkunen. On Scattered Context Grammars. Acta Universitatis Ouluensis, 1973, pp. 75-82.
(pdf) T. Masopust, J. Techet. Leftmost Derivations of Propagating Scattered Context Grammars: A New Proof. unpublished manuscript, 2007, pp. 1-8.
Definitions
A propagating scattered context grammar which uses leftmost or rightmost derivations is a propagating scattered context grammar G = (V, T, P, S) whose language is defined as
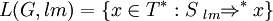
or
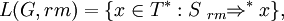
respectively. The family of languages generated by propagating scattered context grammars which use leftmost or rightmost derivations is denoted by
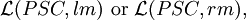
respectively.
Results
Theorem
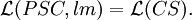
Theorem
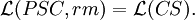
Reduction of Scattered Context Grammars
Based on
(pdf) A. Meduna. Economical Transformations of Scattered Context Grammars to Phrase-Structure Grammars. Acta Cybernetica, 1998, pp. 225-242.
(pdf) A. Meduna. Generative Power of Three-Nonterminal Scattered Context Grammars. Theoretical Computer Science, 2000, pp. 625-631.
(pdf) G. Vaszil. On the Descriptional Complexity of Some Rewriting Mechanisms Regulated by Context Conditions. Theoretical Computer Science, 2005, pp. 361-373.
Definitions
For a scattered context grammar G = (V,T,P,S), its nonterminal complexity is the number of nonterminals in G. If G is a scattered context grammar, then its degree of context-sensitivity, symbolically written as dcs(G), is defined as the number of context-sensitive productions in G. The maximum context sensitivity of G is the greatest number in {len(pi) - 1 : 1 ≤ i ≤ |P|}, symbolically denoted by mcs(G). The overall context sensitivity of G, denoted by ocs(G), is the sum of all members in {len(pi) - 1 : 1 ≤ i ≤ |P|}.
Results
Theorem There are context-sensitive languages which cannot be described by a scattered context grammar G = (V, T, P, S) satisfying |V-T| = 1.
Theorem Every recursively enumerable language is generated by a scattered context grammar G = (V, T, P, S) satisfying |V-T| = 3, dcs(G) = ∞, mcs(G) = ∞, ocs(G) = ∞.
Theorem Every recursively enumerable language is generated by a scattered context grammar G = (V, T, P, S) satisfying |V-T| = 5, dcs(G) = 2, mcs(G) = 3, ocs(G) = 6.
Theorem Every recursively enumerable language is generated by a scattered context grammar G = (V, T, P, S) satisfying |V-T| = 8, dcs(G) = 6, mcs(G) = 1, ocs(G) = 6.
Theorem Every recursively enumerable language is generated by a scattered context grammar G = (V, T, P, S) satisfying |V-T| = 4, dcs(G) = 4, mcs(G) = 5, ocs(G) = 20.
Theorem Let H = (M, T, R, S) be a phrase-structure grammar in Kuroda normal form. Then, there exists a scattered context grammar G = (V, T, P, E) that satisfies
- L(G) = L(H),
- |M| = |V| + 5,
- P contains 4 new context productions,
- P contains 1 new context-free production.
Open Problem Can every recursively enumerable language be described by a scattered context grammar containing only two nonterminals?
Own Research
Generation of Sentences with Their Parses
Based on
(pdf) A. Meduna, J. Techet. Generation of Sentences with Their Parses: the Case of Propagating Scattered Context Grammars. Acta Cybernetica, 2005, pp. 11-20.
(pdf) A. Meduna, J. Techet. Canonical Scattered Context Generators of Sentences with Their Parses. Theoretical Computer Science, 2007, pp. 73-81.
(pdf) J. Techet. Scattered Context Generators of Sentences with Their Parses. Pre-proceedings of the 1st Doctoral Workshop on Mathematical and Engineering Methods in Computer Science, 2005, pp. 68-77.
(pdf) A. Meduna, J. Techet. Reduction of Scattered Context Generators of Sentences Preceded by Their Leftmost Parses. Proceedings of 9th International Workshop on Descriptional Complexity of Formal Systems, 2007, pp. 178-185.
Definitions
We assume that for every scattered context grammar G = (V, T, P, S), there is a set of production labels, denoted by lab(G), such that |lab(G)| = |P|; as usual, lab(G)* denotes the set of all strings over lab(G). Furthermore, there is a bijection from P to lab(G) such that if this bijection maps a production (A1, ..., An) → (x1, ..., xn) to a label l ∈ lab(G), we say that (A1, ..., An) → (x1, ..., xn) is labeled with l, symbolically written as
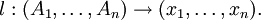
To express that x ⇒* y, where x, y ∈ V*, by using a sequence of productions labeled with p1, p2, ..., pn, we write x ⇒* y [ρ], where ρ = p1...pn ∈ lab(G)*.
Let G = (V, T, P, S) be a scattered context grammar and let S ⇒* x [ρ], where x ∈ T* and ρ ∈ lab(G)*; then, x is a sentence generated by G according to parse ρ. Let lab(G) ⊆ T. G is a proper generator of its sentences with their parses if and only if
![L(G) = \{x : x = y\rho, y \in (T - lab(G))^*, \rho \in lab(G)^*, S \Rightarrow^* x \; [\rho]\};](/en/images/math/8/1/3/81348d79195ba443017c0e76c4e400a0.png)
in addition, if G generates L(G) in a leftmost or a rightmost way, G is a proper leftmost or a proper rightmost generator of its sentences with their parses. Similarly, G is a proper generator of its sentences preceded by their parses if and only if
![L(G) = \{x : x = \rho y, y \in (T - lab(G))^*, \rho \in lab(G)^*, S \Rightarrow^* x \; [\rho]\};](/en/images/math/d/b/2/db2463a482c692050f12d6ba25ccabb5.png)
in addition, if G generates L(G) in a leftmost way, G is a proper leftmost generator of its sentences preceded by their parses. Notice that these definitions impose no restrictions on derivations in a proper leftmost generator. However, every proper leftmost generator G satisfies the property that if G makes a non-leftmost step during a derivation, then this derivation cannot generate a member of L(G). The same applies for proper rightmost generators.
Results
Theorem For every recursively enumerable language L, there exists a propagating scattered context grammar G such that G is a proper generator of its sentences with their parses and L = L(G) // lab(G)+.
Theorem For every recursively enumerable language L there exists a propagating scattered context grammar G = (V', T', P, S) such that G is a proper leftmost generator of its sentences with their parses, |V'-T'| ≤ 6, and L = L(G) // lab(G)+.
Theorem For every recursively enumerable language L there exists a propagating scattered context grammar G = (V', T', P, S) such that G is a proper rightmost generator of its sentences with their parses, |V'-T'| ≤ 6, and L = L(G) // lab(G)+.
Theorem For every recursively enumerable language L there exists a propagating scattered context grammar G = (V', T', P, S) such that G is a proper leftmost generator of its sentences preceded by their parses, |V'-T'| ≤ 6, mcs(G) = 3, and L = lab(G)+ \\ L(G).
Theorem For every recursively enumerable language L there exists a propagating scattered context grammar G = (V', T', P, S) such that G is a proper leftmost generator of its sentences preceded by their parses, |V'-T'| ≤ 9, mcs(G) = 1, and L = lab(G)+ \\ L(G).
References
(pdf) V. Geffert. Context-Free-Like Forms for the Phrase-Structure Grammars. Proceedings of the Mathematical Foundations of Computer Science 1988, 1988, pp. 309-317.
(pdf) H. C. M. Kleijn and G. Rozenberg. On the Generative Power of Regular Pattern Grammars. Acta Informatica, 1983, pp. 391-411.
Generalized k-Limited Erasing
Based on
(pdf) J. Techet. k-Limited Erasing Performed by Scattered Context Grammars. Proceedings of the 2nd International Workshop on Formal Models WFM '07, 2007, pp. 227-234.
Definitions
Let cf((A1, ..., An) → (x1, ..., xn)) = {A1 → x1, ..., An → xn}. The core grammar underlying a scattered context grammar G = (V, T, P, S) is denoted by core(G) and defined as the context-free grammar core(G) = (V, T, cf(P), S) with cf(P) = {A → x : A → x ∈ cf(p) for some p ∈ P}. Let v = u1A1u2A2...unAnun+1 ⇒ u1x1u2x2...unxnun+1 = w [(A1, ..., An) → (x1, ..., xn)]. The context-free simulation of this step by core(G) is denoted by cf(v ⇒ w) and defined as core(G)'s derivation of the form u1A1u2A2...unAnun+1 ⇒ u1x1u2A2...unAnun+1 ⇒n-1 u1x1u2x2...unxnun+1. Let v = v1 ⇒* vn = w be of the form v1 ⇒ v2 ⇒ v3 ⇒ ... ⇒ vn. The context-free simulation of v ⇒* w by core(G) is denoted by cf(v ⇒* w) and defined as v1 ⇒* v2 ⇒* v3 ⇒*...⇒* vn such that for all 1 ≤ i ≤ n-1, vi ⇒* vi+1 is the context-free simulation of vi ⇒ vi+1.
Let S ⇒* x be of the form S ⇒* uAv ⇒* x. Let cf(S ⇒* x) be the context-free simulation of S ⇒* x. Let t be the derivation tree corresponding to S ⇒* x. Consider a subtree rooted at A in t. If the frontier of this subtree is ε, then G erases A in S ⇒* uAv ⇒* x, symbolically written as À, and if this frontier differs from ε, then G does not erase A during this derivation, symbolically written as Á. If o = Á1...Án or o = À1...Àn, we write ó or ò, respectively.
Let G = (V, T, P, S) be a scattered context grammar and let k ≥ 0. G erases nonterminals in a generalized k-limited way in S ⇒* y, where y ∈ L(G), if every sentential form x occurring in S ⇒* y satisfies the following two properties:
- every x = uAeEa, Á, É, è, satisfies |e| ≤ k;
- every x = uAa, Á, satisfies: if ù or à, then |u| ≤ k or |a| ≤ k, respectively.
Set
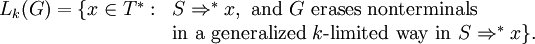
A scattered context grammar G erases its nonterminals in a generalized k-limited way if L(G) = Lk(G). The family of languages generated by scattered context grammars which erase their nonterminals in a generalized k-limited way is denoted by
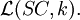
Results
Theorem For each k ≥ 0 and every scattered context grammar G, there is a propagating scattered context grammar G' such that Lk(G) = L(G').
Theorem For every scattered context grammar G which erases its nonterminals in a generalized k-limited way, there exists a propagating scattered context grammar G' such that L(G) = L(G').
Theorem
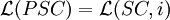
for any positive integer i.
Scattered Context Grammars with Non-Context-Free Components
Based on
(pdf) J. Techet. A Note on Scattered Context Grammars with Non-Context-Free Components. MEMICS 2007 Proceedings, 2007, pp. 225-232.
Definitions
A linear scattered context grammar is a scattered context grammar G = (V, T, P, S), where P is a finite set of productions of the following two forms:
- (S) → (x1A1...xkAkxk+1), where Ai ∈ (V - T) - {S}, xi ∈ T* for all 1 ≤ i ≤ k, for some k ≥ 1,
- (A1, ..., Ak) → (z1, ..., zk), where Ai ∈ (V-T) - {S}, and either zi = xiBiyi, where xi, yi ∈ T*, Bi ∈ (V-T) - {S}, or zi ∈ T* for all 1 ≤ i ≤ k, for some k ≥ 1.
A linear scattered context grammar is of degree n if (S) → (x1A1...xnAnxn+1) ∈ P is a production satisfying n ≥ m for all (S) → (y1A1...ymAmym+1) ∈ P and, in addition, for each p ∈ P, len(p) is constant for every grammar (in other words, len(p) does not depend on the degree). The family of languages generated by linear scattered context grammars of degree n is denoted by
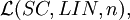
and
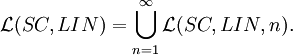
A right-linear scattered context grammar is a linear scattered context grammar G = (V, T, P, S), where P is a finite set of productions of the following two forms:
- (S) → (x1A1...xkAk), where Ai ∈ (V - T) - {S}, xi ∈ T* for all 1 ≤ i ≤ k, for some k ≥ 1,
- (A1, ..., Ak) → (z1, ..., zk), where Ai ∈ (V-T) - {S}, and either zi = xiBi, where xi ∈ T*, Bi ∈ (V-T) - {S}, or zi ∈ T* for all 1 ≤ i ≤ k, for some k ≥ 1.
The family of languages generated by right-linear scattered context grammars of degree n is denoted by
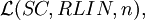
and
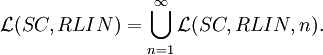
Results
Theorem For each n ≥ 1,
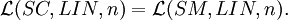
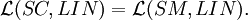
Theorem For each n ≥ 1,
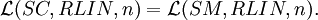
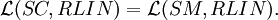
Theorem For each n ≥ 1,
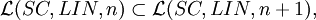
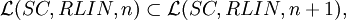
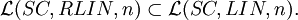
Theorem
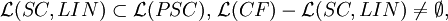
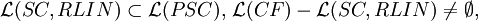
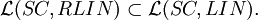
Theorem (Positive Closure Properties) Each family
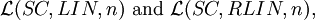
where n ≥ 1, is closed under union, reversal, homomorphism, inverse homomorphism, substitution with regular languages, concatenation with regular languages, intersection with regular languages, left and right quotient by regular languages.
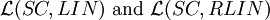
are closed under concatenation.
Theorem (Negative Closure Properties) Each family
where n ≥ 1, is not closed under concatenation with linear languages. Each family
where n ≥ 1, is not closed under concatenation with
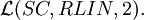
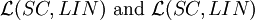
are not closed under intersection, complement and Kleene star.
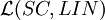
is not closed under substitution with linear languages.
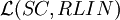
is not closed under substitution with
References
(pdf) O. Ibarra. Simple Matrix Languages. Information and Control, 1970, pp. 359-394.
(pdf) G. Paun. Linear Simple Matrix Languages. Elektronische Informationsverarbeitung und Kybernetik, 1978, pp. 377-384.
Maximal and Minimal Rewriting
Based on
(pdf) A. Meduna, J. Techet. Maximal and Minimal Scattered Context Rewriting. FCT 2007 Proceedings, 2007, pp. 412-423.
Definitions
Let G = (V, T, P, S) be a scattered context grammar. Define a maximal derivation step, max⇒, as u max⇒ v [p], p ∈ P if and only if u ⇒ v [p] and there is no r ∈ P, len(r) > len(p), such that u ⇒ w [r]. Similarly, define a minimal derivation step, min⇒, as u min⇒ v [p], p ∈ P if and only if u ⇒ v [p] and there is no r ∈ P, len(r) < len(p), such that u ⇒ w [r]. Define the transitive and transitive-reflexive closure of maximal and minimal derivation steps in the standard way. The language of G which uses maximal and minimal derivations is denoted by Lmax(G) and Lmin(G) and defined as
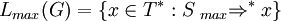
and
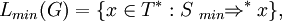
respectively. The corresponding language families are denoted by
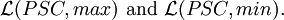
Results
Theorem
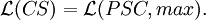
Theorem
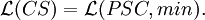
References
(pdf) Takumi Kasai. An Hierarchy Between Context-Free and Context-Sensitive Languages. Journal of Computer and System Sciences, 1970, pp. 492-508.
n-Limited Derivations
Definitions
If u = u1A1...ukAkuk+1 ⇒ u1x1...ukxkuk+1 = v and |u1A1...ukAk|V-T ≤ n, then the derivation step is n-limited and we write u n⇒ v. An n-limited derivation, denoted by x n⇒* y, is a derivation in which every derivation step u j⇒ v satisfies j ≤ n. Define the language of degree n generated by G as L(G,n) = {x ∈ T* : S n⇒* x}. The family of languages of degree n generated by propagating scattered context grammars is denoted by
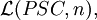
and
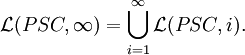
Results
Theorem
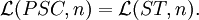
Theorem
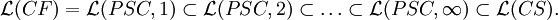
Theorem Every
where n ≥ 1, is an abstract family of languages.
References
(pdf) Takumi Kasai. An Hierarchy Between Context-Free and Context-Sensitive Languages. Journal of Computer and System Sciences, 1970, pp. 492-508.
Related Literature
(pdf) Armin B. Cremers. Normal Forms for Context-Sensitive Grammars. Acta Informatica, 1973, pp. 59-73.
(pdf) H. Fernau. Scattered Context Grammars with Regulation. Annals of Bucharest University, Mathematics-Informatics Series, 1996, pp. 41-49.
(pdf) D. Milgram, A Rosenfeld. A Note on Scattered Context Grammars. Information Processing Letters, 1971, pp. 47-50.
(pdf) J. Techet. Částečně paralelní generování jazyků. Faculty of Information Technology BUT, 2005, pp. 55.
Contact Information
- Address: Jiří Techet, Faculty of Information Technology, Brno University of Technology, Božetěchova 2, Brno 61266, Czech Republic
- Email: techet@fit.vutbr.cz
- Web Page: www.fit.vutbr.cz/~techet
Jiri 23:55, 4 January 2008 (CET)